
Ce matin, c’était le Midterm Exam du MOOC de Princeton sur les statistiques. Pas de pression, le nombre de tentatives était illimité, et de toute façon, ce MOOC n’est pas sanctionné par un certificat.
En le faisant un peu en dilettante, j’ai eu 15/20 au premier essai. Si j’avais été plus attentif, j’aurais pu faire mieux. Mais c’est dire comme le niveau n’est pas trop élevé, car je suis loin d’être satisfait de mon niveau en statistiques.
Reste qu’au fil des semaines, je commence à apprécier ce satané R.
Hier je me suis amusé à faire une petite régression linéaire, simplement par plaisir.
J’ai repris les 12 auteurs de la recommandation sur la fibrillation auriculaire du sujet âgé et je me suis demandé si le nombre de liens d’intérêts était corrélé à la productivité scientifique de ces experts.
On dit bien que l’industrie n’engage que les meilleurs, et donc que les meilleurs ne peuvent qu’avoir des liens d’intérêts. Sous-entendu, ceux qui n’ont pas de liens d’intérêt ne sont pas bons.
J’ai donc compté le nombre de liens d’intérêts des 12 experts et regardé sur PubMed le nombre d’articles dans lesquels ils apparaissent comme auteurs.
Je voulais voir si les deux étaient corrélés.
Comme je suis une bille, j’ai recueilli mes données sur Excel, et je les ai enregistrées en format texte avec séparation des champs par tabulation:
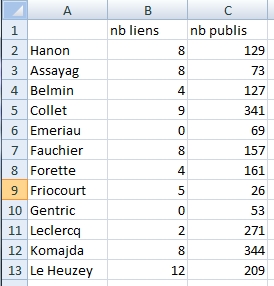 J’ai ouvert RStudio et téléchargé mon fichier texte (nommé COI).
J’ai ouvert RStudio et téléchargé mon fichier texte (nommé COI).
Les lignes de commande sont en bleu.
D’abord quelques statistiques descriptives:
 Le nombre moyen de liens d’intérêts est de 6 (5.67) par auteur, le nombre moyen d’articles publiés est de 163 (163.33).
Le nombre moyen de liens d’intérêts est de 6 (5.67) par auteur, le nombre moyen d’articles publiés est de 163 (163.33).
Et si on faisait maintenant une petite régression linéaire?
 Le coefficient de régression est de 12.245. Mais ce modèle n’est pas statistiquement significatif (p=0.166). Le nombre de liens n’explique que 18.28% de la variance du nombre de publications.
Le coefficient de régression est de 12.245. Mais ce modèle n’est pas statistiquement significatif (p=0.166). Le nombre de liens n’explique que 18.28% de la variance du nombre de publications.
On peut aussi rechercher l’intervalle de confiance du coefficient de régression:
 Il englobe 0 (-6 à 30), ce qui est attendu, étant donné l’absence de significativité du modèle.
Il englobe 0 (-6 à 30), ce qui est attendu, étant donné l’absence de significativité du modèle.
Qu’est-ce ça donne en graphique?
Avec son intervalle de confiance?
(woohoooo!):

 Joli, non?
Joli, non?
On peut aussi normaliser et centrer la régression (scores z):
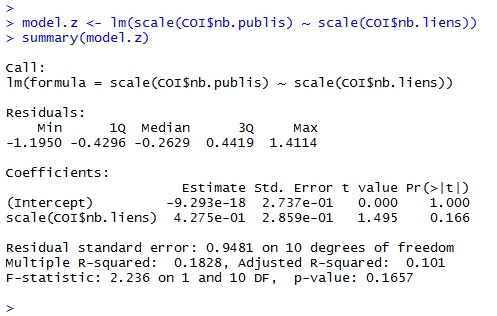 Le coefficient de régression est maintenant de 0.4275.
Le coefficient de régression est maintenant de 0.4275.
Et, si on demandait à R de calculer le coefficient de corrélation?
 Il est de…0.427.
Il est de…0.427.
CQFD
Dans une régression linéaire simple, le coefficient de corrélation est égal au coefficient de régression normalisé.
Mouhahahahahahaha, je fais le singe savant!
C’est grave Docteur?
Vivent les MOOC!
°0°0°0°0°0°0°0°0°0°0°0°0°0°0°0°0°0°
J’ai fait la même chose avec les quelques 60 auteurs de la recommandation de l’ESC 2013 sur l’HTA.
On ne peut pas trouver plus de liens d’intérêts que chez les hypertensiologues, non?
 Malgré cela, là aussi, aucune corrélation entre le nombre de liens d’intérêts et le nombres de publications…
Malgré cela, là aussi, aucune corrélation entre le nombre de liens d’intérêts et le nombres de publications…
(Comme j’ai été assez stupide pour balancer mes données et que j’ai aucune envie de recommencer, il va falloir que vous me fassiez confiance…)

Ahhh que c’est beau ! Vivement qu’ils en refassent un, je veux absolument apprendre à faire aussi des jolies courbes qui expriment avec des jolis dessins qu’il n’y a strictement rien à voir 😉
« Collaborer avec les plus grand nombres » me donnent un joli complément de salaire tous les ans et me permet de partir en vacances là où vont ces salauds de libéraux qui gagnent trop bien leur vie (mouaaaa) ou de payer ma maison secondaire sur la côte…
Est-ce que le fisc est allé voir si notre expert déclare tout ses revenus, je suis impressionné par le nombre d’hospitalier qui oublient de déclarer ce type de revenu, ne paie pas de charges dessus (hé les gars, l’urssaf ça existe !) ? Est-ce que son hôpital lui a demandé combien il touchait par an ? Sa direction, au-dessus d’un certain seuil peut tout à fait considérer qu’il ne respecte pas son obligation d’exclusivité de service public s’il touche la prime qui va avec et donc la sucrer.
Je n’ai qu’une seule question : Jean-Marie, comment trouves-tu le temps de faire tous ces trucs ?
Je dors vite! 😉
Ravi de voir que R te plaît 🙂
Si tu veux modéliser des données à « faible N » (genre, N < 30), tu as tout intérêt à bootstrapper tes modèles, càd. à effectuer plusieurs centaines de modélisations sur des sous-échantillons de tes données. Je t’ai mis le code ici, mais il te faudra les données.
Astuce pour la suite : formate tes données sous forme d’une ligne de code avec
dput(COI), rajoute-les au début de ton code, et mets tout ça sur Gist (voir mon lien), Pastebin, ou même en fin de billet de blog 🙂Wooohoooo, ça devient technique! Tu as encore éloigné l’horizon de R! 😉
Le bootstrap, ça a l’air pas mal (et j’ai découvert un mot)…
Merci!
Bonjour,
L’encadré concrnant les liens d’intérêt est à rapprocher de la théorie de B* L*, virologue émérite, que l’on peut résumer en « Trop de c* tue la c* ».
(Censuré par l’administrateur le 05/11/13)
Bonjour Jean-Marie,
je te lis régulièrement (et je me régale), mais là faut que j’intervienne quand même:
le MOOC de Princeton n’apprend-il pas les conditions d’application de la régression linéaire? les as-tu vérifiées?
La conditions d’application d’un test statistique est ce qui tue le plus les études et entraîne des interprétations foireuses (juste après le biais de sélection et la « mauvaise foi » bien sur)
–Jean
Salut Jean! Content que tu commentes!
Je n’avais pas vérifié les conditions d’application, trop content d’utiliser mon nouveau jouet 😉
J’ai regardé cet après-midi, et évidemment, la distribution n’est déjà même pas normale…
Mouhahahahaha, trop mauvais!
Bon, tu es pardonné par le temps passé aux nouvelles aventures cinématographiques…
je vais vite protéger la maison: ton armée est trop proche!
Juste un mot, pour la frime:
Dans ton plot, s’il y a une relation, elle ne semble pas linéaire => c’est une C.A.* importante à l’origine de nombreux faux négatifs. Mais, bon, la régression non-linéaire, c’est une autre histoire.
*C.A. condition d’application, c’est trop long à écrire
–Jean
Merci 😉 Les stats, c’est un monde vraiment vaste, et en plus j’oublie à mesure. Désespérant, mais passionnant…