Je me suis inscrit au MOOC « Fondamentaux en statistique » de la plateforme FUN par curiosité, et je trouve l’expérience plutôt sympa. Les MOOC francophones se développent, j’avais déjà parlé de celui de la Lorraine University ici.
L’enseignant principal se nomme Avner Bar-Hen, et j’ai eu la très heureuse surprise d’échanger quelques tweets avec lui hier. Pour connaître la démarche ayant conduit à l’organisation de ce MOOC, je vous suggère ce lien.
La plateforme utilisée est une adaptation de celle de EdX, donc pas de mauvaise surprise. Certains devoirs doivent être déposés sur une plateforme externe, mais là-aussi, pas de souci particulier.
Les vidéos de cette première semaine sont claires nettes et précises.
J’ai été très surpris par le format très court des vidéos (autour de 8 minutes), alors que jusqu’à présent mes précédents MOOC m’avaient plutôt habitué à une durée de 15-30 minutes. Difficile de tirer une conclusion au bout de 6 vidéos, mais ce format ultra-court est pas mal et correspond bien à mon emploi du temps un peu trépidant.
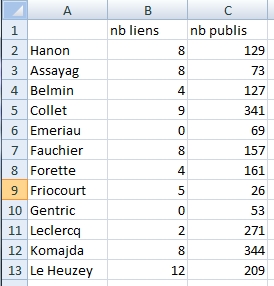
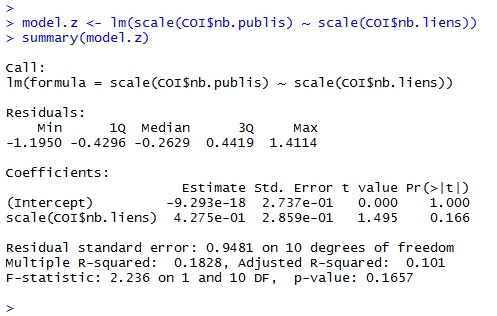
Les quiz sont sympa, et l’exercice d’application m’a fait remettre le nez dans la syntaxe de R, que j’avais presque totalement oubliée après 2-3 semaines de non-utilisation.
Par contre, ce R, quel plaisir de sortir un graphique en boxplot avec une seule ligne de commande: boxplot().
Sur Excel, et bien, c’est tout simplement imbitable… L’exercice d’application m’a aussi fait découvrir la commande quantile().
Comme pour les MOOC que j’ai pu faire précédemment, il faut ne pas se laisser abuser par le « pas/peu de pré-requis ». ll faut avoir l’esprit curieux et savoir ouvrir un autre onglet pour aller chercher son bonheur sur Google. Différents fora de discussion et un wiki permettent et permettront à l’étudiant inscrit de se retrouver un peu si il est perdu.
Sinon, mon opinion des MOOC n’a pas tellement changé.
Les MOOC suivent clairement une courbe de type Technology Hype de Gartner.
Cette démarche est intéressante pour l’esprit curieux qui n’a pas besoin de diplôme, pour le reste (et l’avenir), Wait and See….
Pour conclure, j’aime beaucoup cette phrase de Avner Bar-Hen:
Les MOOCs : c’est une nouvelle ruée vers l’or, on se souviendra plus de la ruée que de l’or.
Ça, c’est chez nous…
Néanmoins, je ne suis pas certain que quelques universités américaines ne fassent pas quand même quelques dollars en vendant à plusieurs milliers d’étudiants avides de « diplômes » US des certificats « vérifiés ».
La preuve, le compte Instagram d’un statisticien américain de l’école bayésienne qui organise des MOOC, d’un cardiologue interventionnel du sud de la France, d’un baron de la drogue mexicain.
Un merveilleux exemple de Narcocorrido.
Mouhahahahahahahaha!