
Je remonte donc doucement mais surement le cours des articles de Significance.
J’ai encore du travail, J’ai lu 2013-2012, il me reste encore 2011-2004…
En décembre 2011, Christopher Weir et Gordon Murray (que je ne connais ne d’Adam ni d’Ève) ont fait publier un excellent petit article: Fraud in clinical trials. Les deux auteurs jouent pour nous aux statisticiens Sherlock Holmes, afin de dépister les fraudes dans les essais cliniques.
L’analyse de la masse considérable de données issues d’un essai clinique (si il est de taille respectable) va permettre d’en déterminer la tendance centrale, la variance, et ainsi de repérer les données aberrantes. De même, des données trop normales doivent éveiller la suspicion. Les auteurs donnent ainsi l’exemple d’un suivi clinique qui aurait lieu tous les lundis de la semaine durant 6 mois. Les aléas de la vie, les vacances… rendent peu probable que chaque patient d’un centre puisse se rendre au jour dit donner leurs données 😉 de façon métronomique. Idem si les intervalles de visites sont invariants.
Les auteurs donnent une foule de petits indices permettant de repérer une fraude.
L’article est excellent, surtout si vous avez déjà participé à un gros essai multi-centrique avec une ARC tatillonne sur les talons (la mienne était biélorusse), et d’interminables séries de données aberrantes (pour le clinicien) à collecter (par exemple, la température d’un frigo neuf, régulier et exact comme une fréquence de quartz, où étaient entreposés les médicaments de l’essai).
Vous voyez ce que je veux dire…
L’article touche au sublime, pour un béotien comme moi, quand il me fait découvrir l’extraordinaire loi de Benford, qui peut permettre de suspecter que des données aient été inventées.
Un chercheur (non statisticien) qui souhaite inventer une donnée, quelle qu’elle soit, va inscrire des nombres « au hasard » dans les petites cases. Ce « hasard » signifie implicitement que chaque nombre de 1 à 9 à la même probabilité probabilité qu’un autre (1/9 ou 11.1.%) d’avoir sa place en première position, en seconde position… de la donnée.
Ben, en fait non!
Le 1 a 30.1% d’apparaître en premier, le 2 17.6%, le 3, 12.5%. Après le troisième chiffre, les probabilités ont tendance à s’égaliser…
Pour en savoir plus sur la loi de Benford:
- Un superbe article de l’excellent DataGenetics
- Pour tester plusieurs bases de données.
- L’article de Wikipedia
Moi aussi, j’ai voulu jouer…
Mais je n’ai pas de données en grand nombre à la maison.
J’ai quand même deux bases de ma vraie vie pas trop petites: le nombre de visites sur 499 de mes billets les plus lus et le nombre de visiteurs amenés par mes 424 plus importants adresseurs.
(Merci WordPress pour ces statistiques…)
Si je prends chacun des premiers chiffres du nombre de visites de mes 499 billets les plus lus, j’obtiens la distribution suivante:

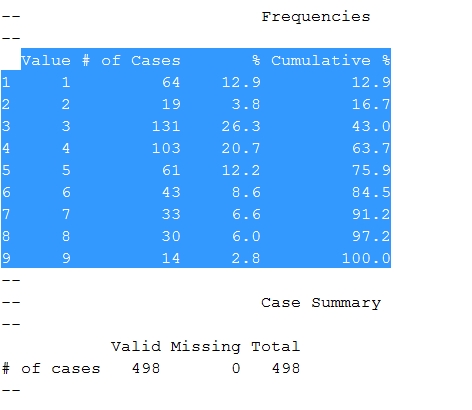 Pareil pour les adresseurs:
Pareil pour les adresseurs:
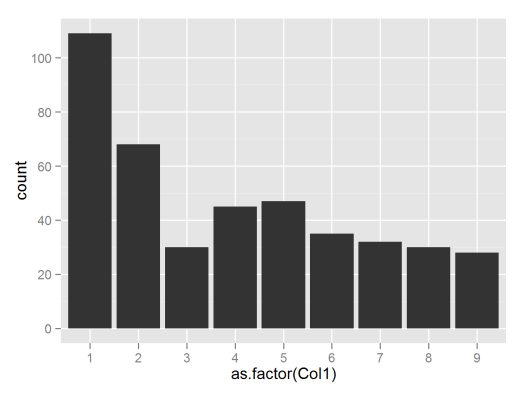
 Ça colle pas trop mal à la loi de Benford, étant donné la petite taille de mes séries, non ?
Ça colle pas trop mal à la loi de Benford, étant donné la petite taille de mes séries, non ?
